Why leaders struggle to balance innovation and stability
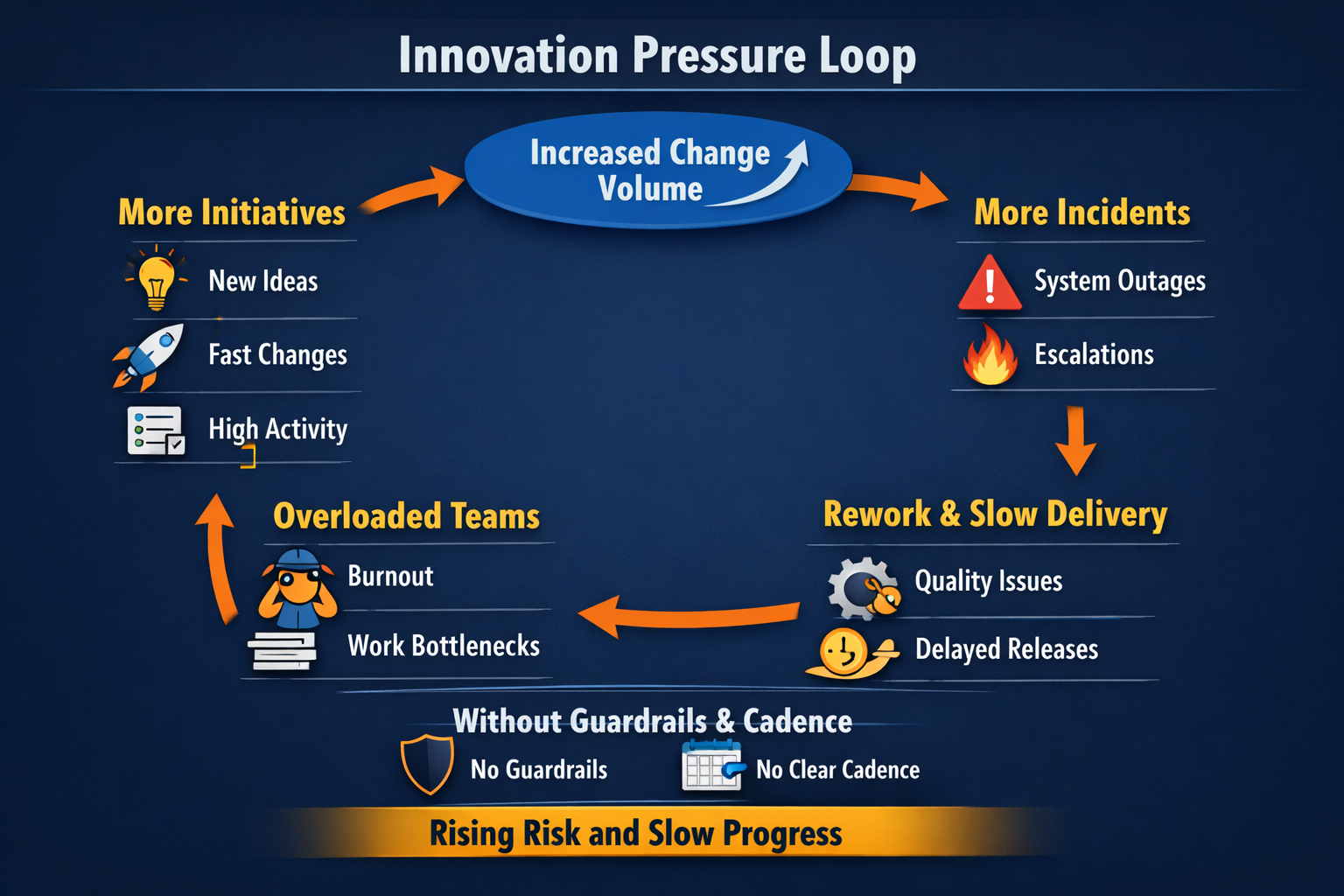
Leaders do not choose to destabilize operations. They choose speed, growth, and competitive response. Instability shows up later when change volume rises faster than operational control.
The trap looks like progress. Teams start more initiatives, executives see more activity, and the organization feels busy. Then your delivery system absorbs the cost. Releases slow because teams spend more time coordinating. Incidents rise because change risk increases. Quality drops because testing and rollout discipline erodes under deadline pressure.
Balance does not mean splitting time evenly. Balance means you define what must remain stable, what can be experimental, and what conditions must be true before work moves into production. Leaders own this design. It also helps to tie this work to the same operating discipline used in execution planning so innovation pressure does not bypass prioritization.
The three forces that create instability
1. Unbounded change
Every new initiative adds change into production. Change increases the number of failure paths. If you do not manage the rate of change, you will manage the consequences of change.
- More releases increase the chance of a bad interaction between components.
- More parallel work increases dependency coordination and handoffs.
- More scope increases testing complexity and rollout risk.
2. Invisible operating costs
New capabilities require on-call ownership, monitoring, alerts, dashboards, incident routines, and training. If planning stops at launch, teams carry hidden operational work that never shows up in project plans.
- Alert noise rises. Engineers lose time and confidence.
- Support escalations increase. Work gets interrupted.
- Runbooks stay missing. Recovery slows.
3. Decision friction and priority thrash
When decision rights are unclear, leaders resolve conflicts through escalation. Escalations bypass sequencing and increase work in progress. Work in progress is where delivery time goes to die.
- Teams start work without clear acceptance criteria.
- Scope expands through small add-ons without re-baselining value.
- Leaders ask for speed while quality controls weaken.
Signals you are drifting into instability
Most organizations notice drift after the pain is visible. You can catch it earlier. Treat these as signals of an operating system under stress, not isolated problems.
- Change failure rises. More releases trigger incidents, rollbacks, or hotfixes.
- Unplanned work grows. Engineers spend more time on outages and support than planned delivery.
- Lead time increases. Work takes longer from approval to production even when teams stay busy.
- Release cadence becomes irregular. Big batches replace smaller controlled releases.
- On-call concentration increases. A few people carry incident knowledge and burn out.
- Customer feedback shifts. Complaints move from missing features to reliability and performance.
What balance looks like in practice
Balance is intentional design. You set clear boundaries between experiments and production change. You reserve capacity for stability work. You apply consistent entry and exit criteria. You review metrics on a schedule and make decisions while there is still time to correct.
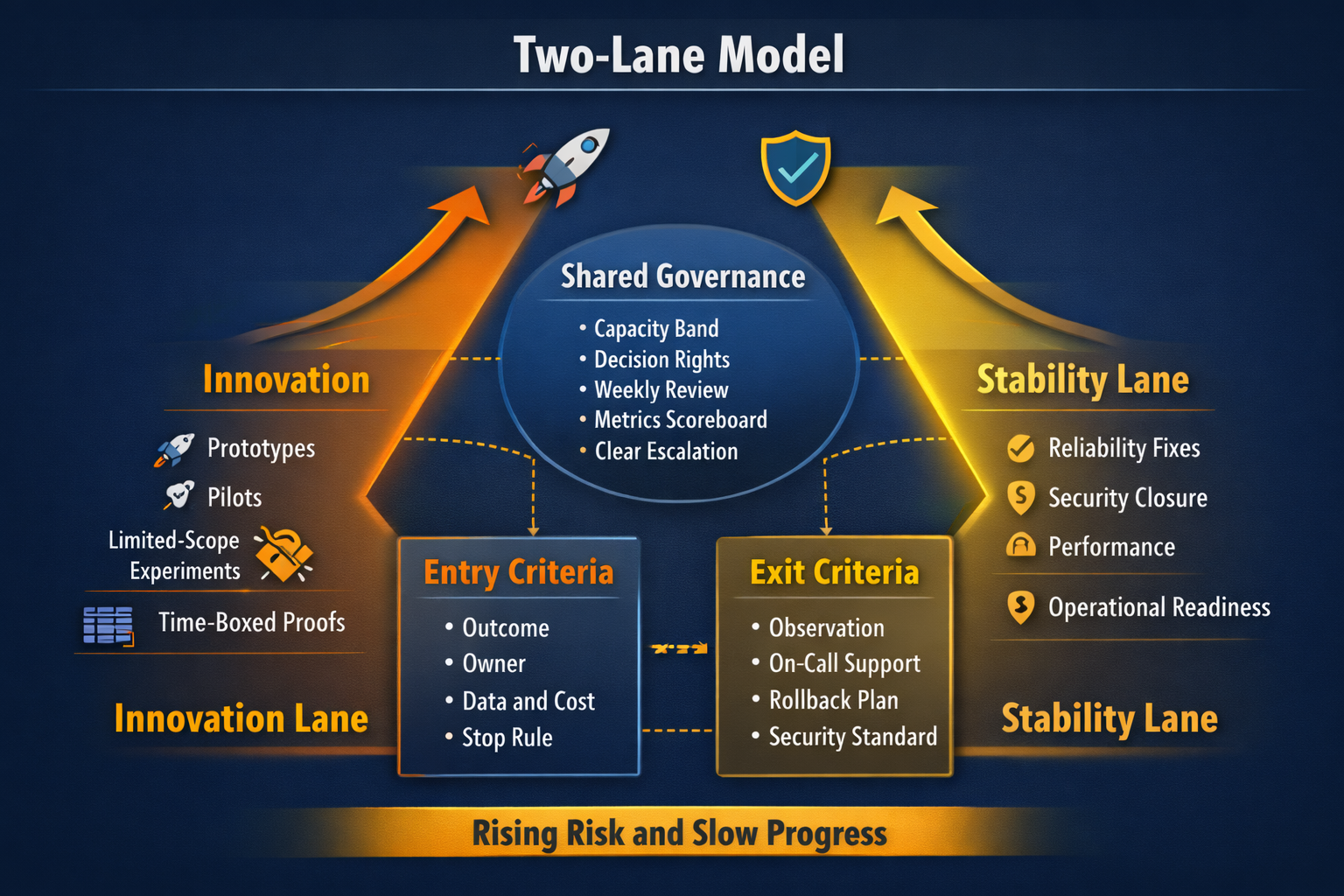
Two lanes, one operating model
Separate work into two lanes. Keep one leadership cadence. This avoids silos while still containing risk.
- Innovation lane. Prototypes, pilots, limited-scope experiments, and time-boxed proofs.
- Stability lane. Reliability fixes, security closure, performance, resilience, and operational readiness improvements.
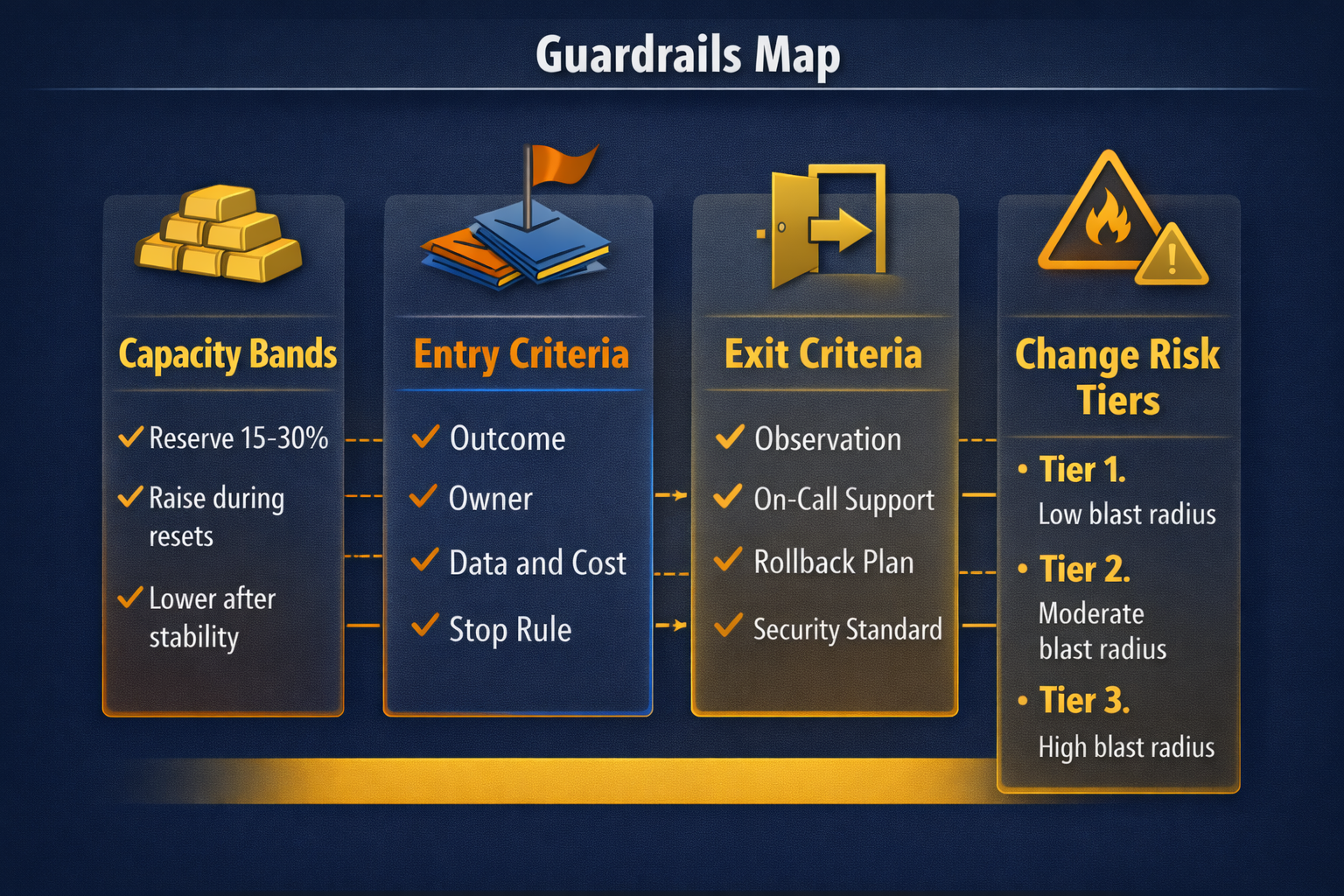
Guardrails leaders should set
Guardrails prevent debates from restarting every week. They set expectations, reduce thrash, and protect teams from impossible tradeoffs. Keep guardrails few, explicit, and enforceable.
Guardrail 1. Capacity allocation bands
Set an explicit capacity band for stability work. Do not treat it as leftover time. Most organizations start at 15 to 30 percent depending on incident load, compliance needs, and technical debt.
- Start with a stability band that matches current incident reality.
- Raise the band temporarily during high-risk migrations or reliability resets.
- Lower the band only after metrics show sustained stability.
Guardrail 2. Entry criteria for innovation work
Teams move faster when leadership demands clarity up front. Require these minimum inputs before approving an experiment.
- Outcome statement in one sentence with a timeframe.
- Named owner accountable for decisions and delivery.
- Data access and classification confirmed.
- Cost cap and time box.
- Defined stop rule and exit criteria.
Guardrail 3. Exit criteria before production exposure
Exit criteria keeps pilots from turning into permanent spend and permanent risk. Define what must be true before work graduates into a production commitment.
- Monitoring and alerting standards met.
- On-call ownership named and trained.
- Rollback plan tested and documented.
- Security and privacy requirements confirmed.
- Support path defined for business users.
Guardrail 4. Change risk tiers
Not every change deserves the same review. Risk tiers let low-risk work move fast while high-risk change gets deeper controls.
- Tier 1. Low blast radius. Standard testing and automated rollout.
- Tier 2. Moderate blast radius. Added review and staged rollout.
- Tier 3. High blast radius. Senior review, change window, rehearsed rollback.
Decision rights that prevent escalation-driven delivery
Balance fails when decisions are distributed without accountability. You want one owner per decision and one clear escalation path. This speeds delivery because teams stop waiting for consensus.
- Business owner. Accountable for outcomes and adoption.
- Technology owner. Accountable for reliability, integration, and operating impact.
- Security and risk owner. Accountable for controls, exceptions, and evidence.
- Finance partner. Accountable for burn tracking and renewal leverage.
The weekly executive review that protects both sides
Cadence is the control system. Without cadence, teams negotiate tradeoffs in the middle of incidents. Run one weekly review with a short agenda and a one-page summary.
Weekly agenda
- Outcome progress. What moved, what did not, and why.
- Risk closure. Top risks, owners, and closure dates.
- Burn versus value. Spend and capacity consumed versus measurable progress.
- Change calendar. High-risk releases and required controls.
- Stop decisions. What will pause, retire, or defer to protect focus.

Metrics leaders should track
Use a small scoreboard and tie it to decisions. When metrics are too many, leaders stop using them. When metrics are unclear, teams debate definitions instead of shipping.
Reliability and customer impact
- Availability or error rate for core services.
- Customer-impacting incident count.
- Time to restore service after a major incident.
Change quality
- Change failure rate.
- Rollback frequency.
- Hotfix rate in the week after release.
Delivery flow
- Lead time from approval to production.
- Work in progress per team.
- Percent of capacity reserved for stability.
Common scenarios and what leaders should do
Scenario. A growth initiative requires risky platform change
Leaders often push risky change under a growth deadline. The better move is to separate the initiative into a proof milestone and a production readiness plan. Approve the proof milestone first. Fund the stability work required for production readiness in parallel.
- Define a limited-scope proof that validates business value.
- Define production readiness requirements and owners.
- Stage rollout with risk tiers and a clear rollback plan.
Scenario. Incident load keeps eating delivery capacity
This is a signal that stability work is underfunded or poorly targeted. Reset by focusing stability capacity on repeat incident drivers and operational maturity. Pause new high-risk change until the curve improves.
- Rank the top incident drivers and assign owners.
- Fund fixes that remove repeat pages, not one-off patches.
- Improve observability and runbooks for the most critical services.
Scenario. Innovation feels slow because governance feels heavy
Governance feels heavy when it is vague. Make it lighter by using clear guardrails and tiered reviews. Low-risk experiments should move fast under a defined cost cap and stop rule.
- Use standard templates for outcomes, owners, cost caps, and stop rules.
- Limit committees. Name the decision owner and publish it.
- Implement change risk tiers and a basic change calendar.
- Start the weekly executive review with the one-page template.
Leaders dealing with repeated delivery drag should also look at how accountability is distributed across teams. This is closely related to the operating discipline covered in creating accountability across technology teams.
30, 60, 90 day implementation plan
First 30 days. Establish control
- Define core services, owners, and reliability targets.
- Set change risk tiers and publish release controls for Tier 3 work.
- Set the weekly executive review and agree on the one-page inputs.
- Set an initial stability capacity band and publish it.
Days 31 to 60. Build guardrails and readiness
- Roll out entry and exit criteria for pilots and production work.
- Standardize monitoring, alerting, and on-call ownership expectations.
- Target top incident drivers with stability capacity.
- Reduce work in progress and publish stop decisions.
Days 61 to 90. Improve change quality and reduce drag
- Improve release discipline, staged rollouts, and rollback rehearsals for Tier 3 changes.
- Reduce change failure rate and track the trend weekly.
- Adjust capacity bands based on stability results.
- Confirm which pilots graduate and which stop.
By this point, leadership should have a stable review rhythm, clearer decision rights, and better visibility into where innovation helps growth versus where it adds unmanaged risk.
Frequently Asked Questions
What does balancing innovation and operational stability mean?
Balance means shipping meaningful new work while meeting defined reliability targets for core services. Leaders keep tradeoffs explicit through guardrails, ownership, and a weekly review cadence.
How much capacity should we reserve for stability work?
Start by reserving 15 to 30 percent of delivery capacity for stability, based on incident load and operational debt. Increase it when change failure and unplanned work rise, and lower it only after the scoreboard trends improve for multiple weeks.
What guardrails keep experiments from destabilizing production?
Require a named owner, a measurable success signal, and clear entry and exit criteria before work starts. Enforce production readiness for anything touching core services, including monitoring, rollback, and support ownership.
Which metrics show we are drifting out of balance?
Track change failure rate, lead time to production, incident volume, time to restore service, and percent of capacity consumed by unplanned work. When these trend worse, innovation pressure is leaking into core operations.
What is the fastest reset when incidents keep rising?
Freeze new high-risk change for a short window, stabilize the top incident drivers, and re-rank the portfolio to reduce parallel work. Restart innovation through a controlled lane with checkpoints and a weekly operating review.
Want a plan that protects innovation and stability?
Bring one growth initiative and one core service. A working session will map guardrails, owners, risk tiers, and a 90-day cadence your leadership team can run.
Book a consultation